
算法原理概述
MD5信息摘要算法,( Message-Digest Algorithm 5),是一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值,用于确保信息传输完整一致。
MD5算法使用little-endian(小端模式,即低位字节存在内存低地址),输入任意不定长度信息,算法都首先将其以512-bit进行分组(不足补位),每个512-bit的分组都和四个32-bit的数据一起,进行4次大循环(共64次迭代),并更新这四个32-bit数据。当所有分组都经过上述操作后,最后得到的四个32-bit联合输出固定的128位信息摘要。
算法基本流程
算法的基本过程为:填充、分块、缓冲区初始化、循环压缩、得出结果。
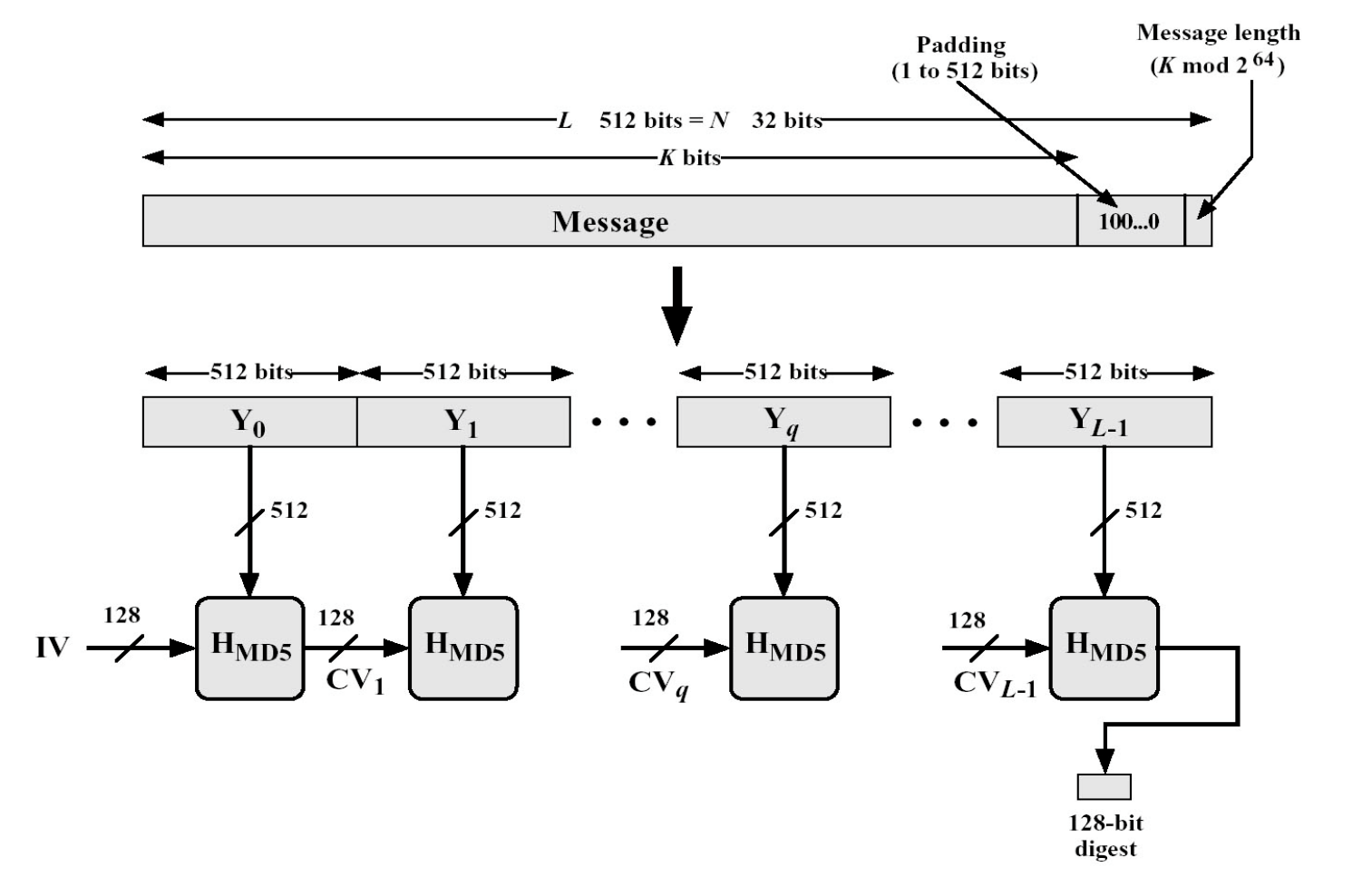
总体结构
MD5算法的总体结构如上图所示,结构应该还算是比较清晰的。与上次的DES加密算法不同,MD5的主体只有一个压缩函数,我们只需要写好这个函数中的内容,其他都比较简单。
我认为最主要的关键点有两个:
- 如何对于数据的填充和分块,特别是当输入是以一个文件而不是一个短字符串的形式时;
- 如何进行算法中的64次迭代。
下面对于算法的流程进行一些简单的说明:
数据填充和分块
在长度为 K-bit 的原始消息数据尾部填充长度为 P-bit 的标识 100…0(一位1后面接若干位0),1 < P < 512(即至少要填充1个bit),使得填充后的消息位数为:K + P $\equiv$ 448 (mod 512). 其中,如果当 K $\equiv$448 (mod 512) 时,需要P = 512。
再向上述填充好的消息尾部附加 K 值的低64位(即K mod $2^{64}$), 最后得到一个总长度位数为K + P+ 64 $\equiv$ 0 (mod 512) 的消息。
得到填充完毕后的消息以后,我们就可以将其恰好分为 L 个 512-bit 的分组。(同时每个分组也可以再细分成16个 32-bit 的小分组,在程序中我们可以使用一个数组保存起来,这在后续的压缩循环中会使用到)
初始化
初始化一个128-bit 的 MD 缓冲区,初始记为CV0,可以表示成4个32-bit 寄存器(A, B, C, D),后续的迭代始终在 MD 缓冲区进行,最后一步的128-bit 输出即为MD5算法的结果。
CV0的初始值为IV。寄存器(A, B, C, D) 置16进制初值作为初始向量IV,并采用小端存储(little-endian) 的存储结构(Intel x86系列CPU原本就采用Little Endian 方式存储):
- A= 0x67452301
- B= 0xEFCDAB89
- C= 0x98BADCFE
- D= 0x10325476
压缩循环
经过上述初始化步骤后,就可以开始执行算法的总体部分了,也就是压缩函数。
压缩函数每次都从CV(即上文提到的 128-bit 缓冲区)输入128位,从之前分好的消息分组中按顺序输入512位,完成4轮循环后,得到该轮压缩的128位结果,加到原来的缓冲区中,然后用下一分组继续上述步骤。(说具体一点,就是函数每次都从缓冲区(A, B, C, D)拿到四个数a, b, c, d,然后对于a, b, c, d进行压缩循环操作,把最后得到的结果a, b, c, d加到原来的(A, B, C, D)中,下一次函数执行再从(A, B, C, D)中拿数据)
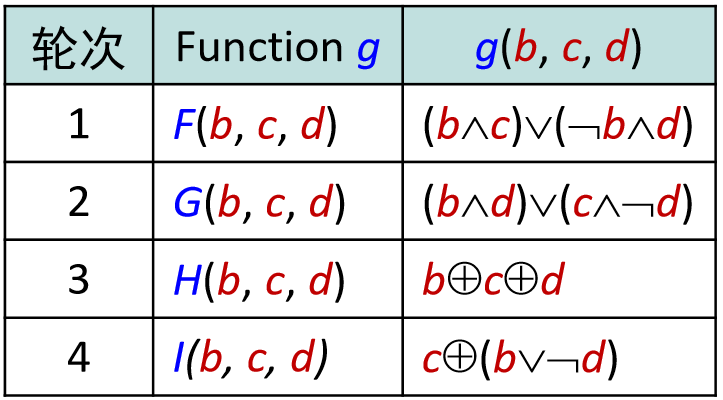
上文提到函数共4轮循环,其中每轮循环分别固定不同的生成函数F, G, H, I,结合指定的T表元素T[]和消息分组的不同部分X[]做16次迭代运算, 生成下一轮循环的输入。即4轮循环共有64次迭代运算。每轮的逻辑如下:
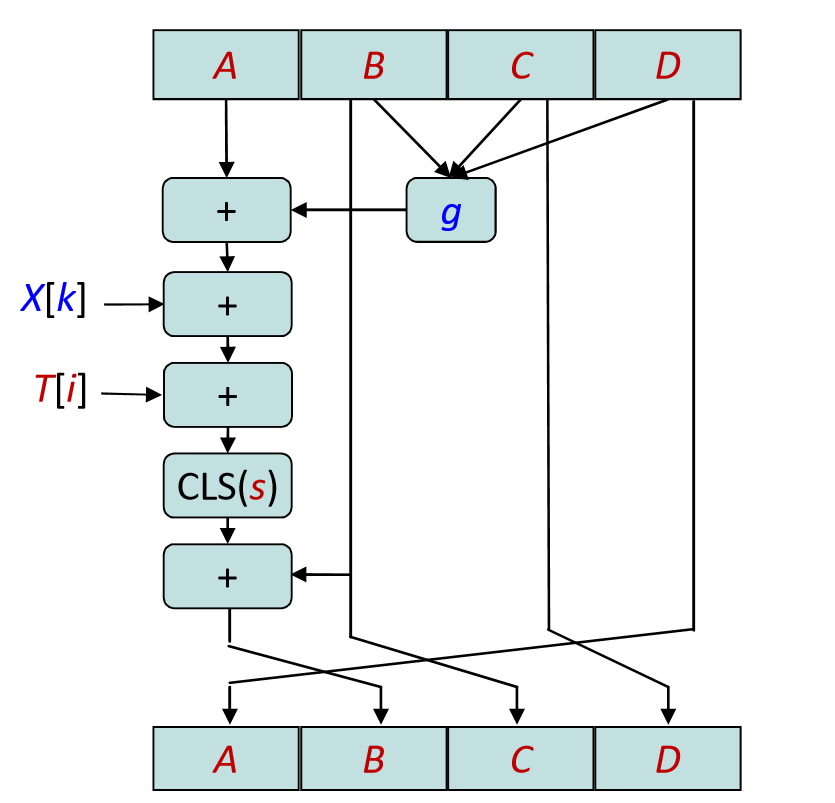
生成函数g
X[k]
定义为当前处理消息分组的第k个(k= 0..15) 32位字(上文曾提到要将512-bit的分组再分为16个 32-bit 的小分组)。
k值的选取,设 j = i - 1:
- 第1轮循环:k = j,即顺序使用X[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
- 第2轮循环:k = (1 + 5j) mod 16,即顺序使用X[1, 6, 11, 0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12]
- 第3轮循环:k = (5 + 3j) mod 16,即顺序使用X[5, 8, 11, 14, 1, 4, 7, 10, 13, 0, 3, 6, 9, 12, 15, 2]
- 第4轮循环:k= 7j mod 16,即顺序使用X[0, 7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9]
T[i]
T 表的第i个元素,每个元素为32位字;T表总共有64个元素,也称为加法常数。具体数值由于篇幅限制不再列出,具体可见程序。
CLS(s)
循环左移s位。64次迭代中,每一次迭代左移的位数s如下:
- s[ 1..16] = { 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22 }
- s[17..32] = { 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20 }
- s[33..48] = { 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23 }
- s[49..64] = { 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21 }
加法
循环中的加号表示的是模$2^{32}$ 加法。
模块分解
按照算法的流程以及实际程序编写的需要,总体上我们可以分解得到以下模块:
读取文件和补位模块
为了更贴合实际情况,本程序实现对于文本文件中内容的散列值计算,即可以支持任意位数字符。
我们无需按照死板的思维,一开始就马上统计文件所包含的比特数,然后马上计算出该如何如何进行补位。实际上,正是由于文件指针的存在,使得我们可以对于整个文件进行实时处理,也就是说我们只需要维护一个count变量,其初始值等于0。而我们每次读取文件64个字节(8*64=512),然后对于读到的这个消息分组即时进行压缩,同时累计位数到count上,直到我们读到文件的末尾,意味着此时不足512字节了。注意,由于我们一直在统计读到的位数,那么此时我们就得到了文件总大小,然后就可以对于最后的不足512bit的部分进行相应的补位操作了。
本文对应的程序就使用了上述方法。
主循环模块
主循环就是上文提到的压缩循环部分,输入为文件读取模块得到的512bit文本数据和上一轮循环得到的CV值(A, B, C, D),经过64次迭代后更新CV值,用于下一次新的循环。最终,随着文本读取的结束,也就得到了最终结果。
输入输出模块
输入输出模块就比较简单了,由用户输入要进行处理的文件,最后输出得到的结果(32个16进制数的形式)。
数据结构
本程序中没有使用到特殊的数据结构。只需要对于算法中会使用到的一些表和运算进行预先记录,可方便后续的操作,例如前文提到的生成函数、T表、循环左移的s值等等。
C语言源代码
注释已经比较详细,这里不再进行说明。
md5.h
1 |
|
main.c
1 |
|
编译运行结果
运行环境:💻Windows 10 1903
IDE:Visual Studio 2017
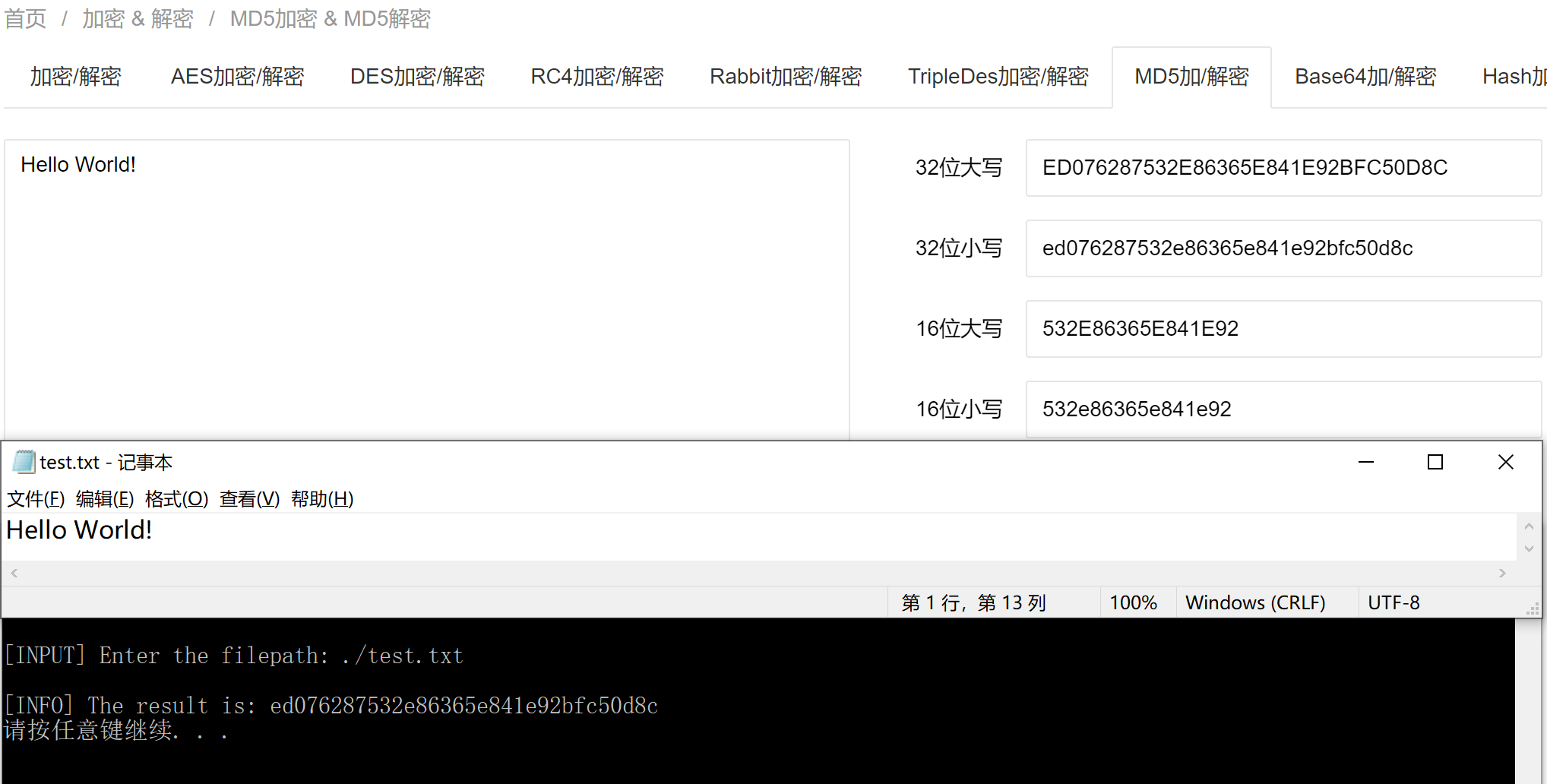
测试方式:和网上的已有MD5在线算法得到的结果进行比较,验证正确性。
注意:在使用本程序时,需要将文件放在正确的路径下
短字符串
使用短字符Hello World!进行测试:
长字符串
使用长达157个字符的字符串进行测试:
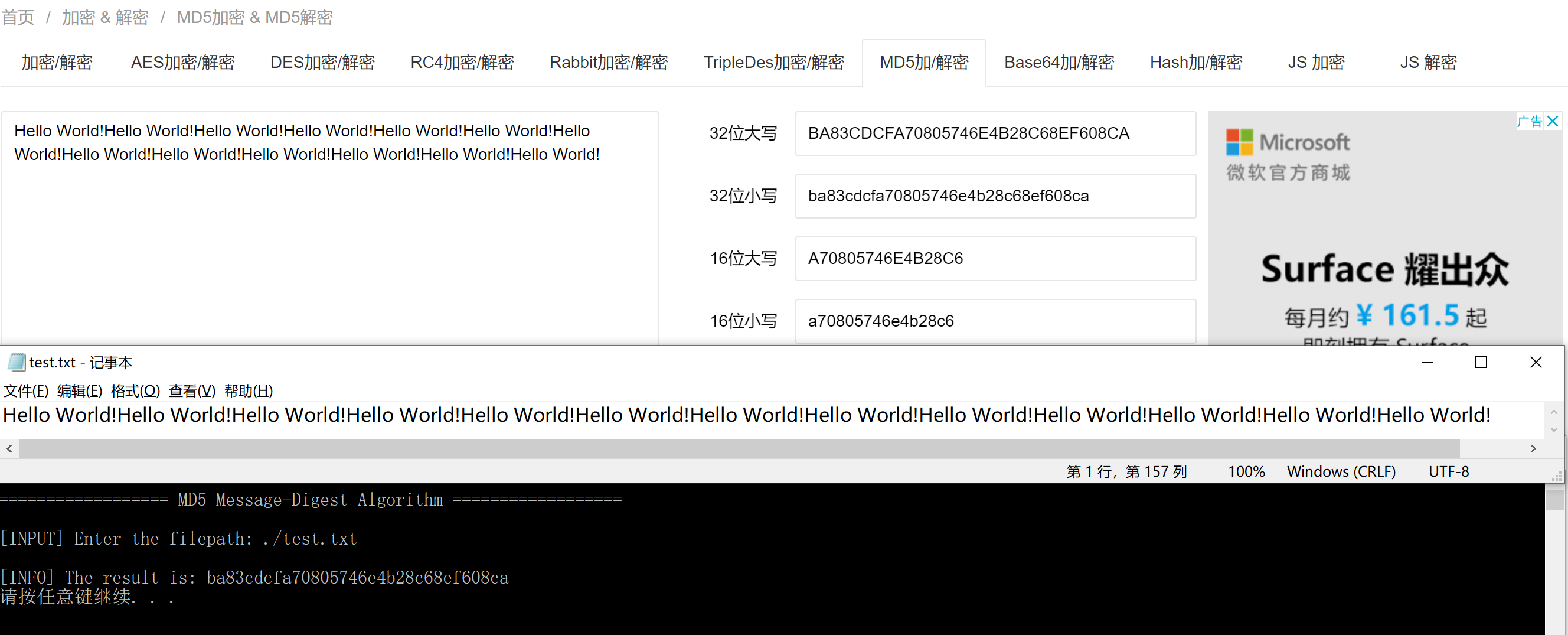
与网上的结果均一致,测试通过。